Non c’è niente di nuovo nell’uso dell’intelligenza artificiale (AI) nell’elaborazione video. Se guardi oltre l’elaborazione delle immagini, è uno dei casi d’uso più comuni per l’intelligenza artificiale. E proprio come l’elaborazione delle immagini, l’elaborazione video utilizza tecniche consolidate comecomputer vision , riconoscimento di oggetti, machine learning e deep learning per migliorare questo processo.
Sia che utilizzi la visione artificiale e la PNL nell’editing e nella generazione di video , il riconoscimento di oggetti nelle attività di codifica automatica dei contenuti video , l’apprendimento automatico per semplificare l’ analisi video AI o il deep learning per accelerare la rimozione dello sfondo in tempo reale , i casi d’uso continuano a crescere giorno.
Continua a leggere per scoprire quale approccio puoi adottare quando si tratta di utilizzare l’intelligenza artificiale nell’elaborazione video.
Le basi dell’elaborazione video in tempo reale
Cominciamo con le basi. L’elaborazione video in tempo reale è una tecnologia essenziale nei sistemi di sorveglianza che utilizzano il riconoscimento di oggetti e volti. È anche il processo di riferimento che alimenta il software di ispezione visiva AI nel settore industriale.
Quindi, come funziona l’elaborazione video? L’elaborazione video prevede una serie di passaggi, che includono decodifica, calcolo e codifica. Ecco cosa devi sapere:
Decodifica: il processo necessario per convertire un video da un file compresso al suo formato raw.
Calcolo: un’operazione specifica eseguita su un fotogramma video grezzo.
Codifica: il processo di riconversione del fotogramma elaborato al suo stato compresso originale.
Ora, l’obiettivo di qualsiasi attività di elaborazione video è completare questi passaggi nel modo più rapido e accurato possibile. I modi più semplici per farlo includono: lavorare in parallelo e ottimizzare l’algoritmo per la velocità. In parole povere? È necessario sfruttare la suddivisione dei file e l’architettura della pipeline.
Che cos’è la divisione dei file video?
La suddivisione dei file video consente agli algoritmi di funzionare contemporaneamente, consentendo loro di utilizzare modelli più lenti e accurati. Ciò si ottiene suddividendo i video in parti separate che vengono poi elaborate contemporaneamente.
Puoi pensare alla divisione del video come a una forma di generazione di file virtuali piuttosto che alla generazione di file secondari.
Nonostante ciò, la suddivisione dei file video non è l’opzione migliore per l’elaborazione video in tempo reale. Perché esattamente? Questo processo rende difficile mettere in pausa, riprendere e riavvolgere un file durante l’elaborazione.
Che cos’è l’architettura della pipeline?
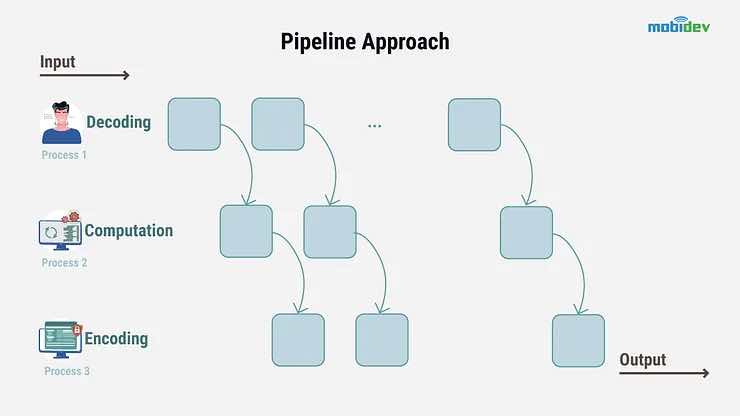
L’altra opzione è l’architettura della pipeline. Questo processo funziona per dividere e parallelizzare le attività eseguite durante l’elaborazione, piuttosto che dividere completamente il video.
Ecco un rapido esempio di come appare in pratica l’architettura della pipeline e di come può essere utilizzata in un sistema di videosorveglianza per rilevare e sfocare i volti in tempo reale.
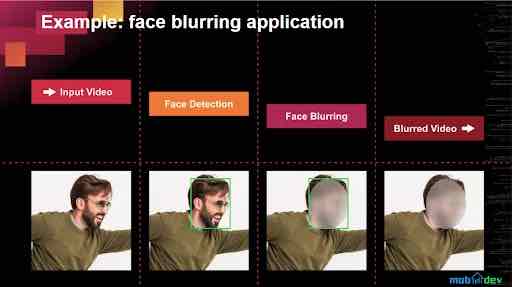
In questo esempio, la pipeline ha suddiviso le attività in decodifica, rilevamento dei volti, sfocatura dei volti e codifica. E se vuoi migliorare la velocità della pipeline, puoi utilizzare le tecniche di deep learning della pipeline .
Decodifica e codifica spiegate
E la decodifica e la codifica? Ci sono due modi per completare questi processi: software e hardware.
Potresti già avere familiarità con il concetto di accelerazione hardware. Questo processo è reso possibile grazie ai decoder e agli encoder installati nelle ultime schede grafiche NVIDIA, nonché ai core CUDA.
Quindi, quali opzioni hai a disposizione quando si tratta di accelerazione hardware per i processi di codifica e decodifica? Ecco alcune delle opzioni più popolari:
Compila OpenCV con il supporto CUDA: la compilazione di OpenCV con CUDA ottimizza sia la decodifica che qualsiasi calcolo della pipeline che utilizza OpenCV. Tieni presente che dovrai scriverli in C++ poiché il wrapper Python non lo supporta. Ma in situazioni che richiedono sia la decodifica che i calcoli numerici con una GPU senza copiare dalla memoria della CPU, è ancora una delle scelte migliori disponibili.
Compila FFmpeg o GStreamer con supporto per codec NVDEC/NVENC: Un’altra opzione è utilizzare il decoder e l’encoder NVIDIA integrati inclusi con le installazioni personalizzate di FFmpeg e Gstreamer. Tuttavia, suggeriamo di utilizzare FFmpeg, se possibile, poiché richiede meno manutenzione. Inoltre, la maggior parte delle librerie è alimentata da FFmpeg, il che significa che aumenterai automaticamente le prestazioni della libreria sostituendola.
Usa NVIDIA Video Processing Framework: l’ultima opzione consiste nell’utilizzare un wrapper Python per decodificare il frame direttamente in un tensore PyTorch sulla GPU. Questa opzione rimuove la copia extra dalla CPU alla GPU.
Rilevamento viso e sfocatura
I modelli di rilevamento degli oggetti (SSD o RetinaFace) sono un’opzione popolare per completare il rilevamento dei volti. Queste soluzioni funzionano per individuare il volto umano in una cornice. E in base alla nostra esperienza , tendiamo a preferire i modelli Caffe Face tracking e TensorFlow di rilevamento oggetti poiché hanno fornito i migliori risultati. Inoltre, entrambi sono disponibili utilizzando il modulo dnn della libreria OpenCV .
Quindi, cosa succede dopo che è stato rilevato un volto? Successivamente, il sistema basato su Python e OpenCV rivelerà i riquadri di delimitazione e la sicurezza del rilevamento. Infine, alle aree ritagliate viene applicato un algoritmo di sfocatura.
Come puoi creare un software di elaborazione video live basato sull’intelligenza artificiale?
Non è un segreto che l’elaborazione video, i codec che la alimentano e sia l’hardware che il software richiesti siano di natura piuttosto tecnica.
Tuttavia, ciò non significa che non puoi utilizzare questi strumenti per creare il tuo software di elaborazione video dal vivo.
Ecco una breve descrizione di ciò che devi fare:
Inizia regolando la tua rete neurale pre-addestrata per completare le attività richieste.
Configura la tua infrastruttura cloud per gestire l’elaborazione video e scalarla secondo necessità.
Crea un consulente software per condensare il processo e integrare casi d’uso specifici come applicazioni mobili e pannelli di amministrazione o web.
Lo sviluppo di un MVP per un software di elaborazione video simile può richiedere fino a quattro mesi utilizzando una rete neurale pre-addestrata e semplici livelli applicativi. Tuttavia, l’ambito e la tempistica dipendono dai dettagli di ciascun progetto. Nella maggior parte dei casi, ha senso iniziare con lo sviluppo di Proof of Concept per esplorare le specifiche del progetto e trovare un flusso ottimale.
