Rendering neurale: quanto in basso puoi scendere in termini di input?
Martin Anderson da unite.ai

Ieri alcuni nuovi straordinari lavori sulla sintesi di immagini neurali hanno catturato l’attenzione e l’immaginazione di Internet, poiché i ricercatori Intel hanno rivelato un nuovo metodo per migliorare il realismo delle immagini sintetiche.
Il sistema, come dimostrato in un video di Intel, interviene direttamente nella pipeline di immagini per il videogioco Grand Theft Auto V e migliora automaticamente le immagini attraverso un algoritmo di sintesi di immagini addestrato su una rete neurale convoluzionale (CNN), utilizzando immagini del mondo reale dal set di dati Mapillary e sostituendo l’illuminazione e le texture meno realistiche del motore di gioco GTA.
I commentatori, in una vasta gamma di reazioni in comunità come Reddit e Hacker News, stanno postulando non solo che il rendering neurale di questo tipo potrebbe sostituire efficacemente l’output meno fotorealistico dei motori di gioco tradizionali e CGI a livello di VFX, ma che questo processo potrebbe essere ottenuto con un input di base molto maggiore di quello dimostrato nella demo Intel GTA5, creando in modo efficace input proxy “fantoccio” con output estremamente realistici.
Il principio è stato esemplificato da una nuova generazione di sistemi GAN e codificatore / decodificatore negli ultimi tre anni, come GauGAN di NVIDIA , che genera immagini sceniche fotorealistiche da imbrattamenti grezzi.
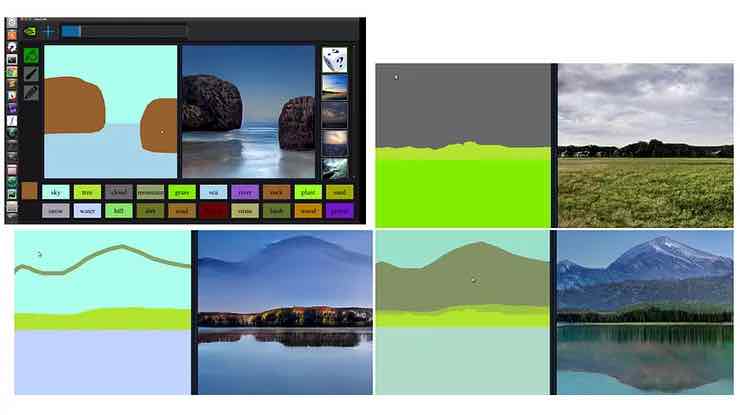
In effetti, questo principio capovolge l’uso convenzionale della segmentazione semantica nella visione artificiale da un metodo passivo che consente ai sistemi della macchina di identificare e isolare gli oggetti osservati in un input creativo, in cui l’utente ‘dipinge’ una falsa mappa di segmentazione semantica e il sistema genera immagini coerenti con le relazioni che comprende per aver già classificato e segmentato un particolare dominio, come lo scenario.

Un framework di apprendimento automatico applica la segmentazione semantica a varie scene esterne, fornendo il paradigma architettonico che consente lo sviluppo di sistemi interattivi, in cui l’utente dipinge un blocco di segmentazione semantica e il sistema riempie il blocco con immagini appropriate da un set di dati specifico del dominio, come Set di visualizzazione stradale Mapillary della Germania, utilizzato nella demo di rendering neurale GTA5 di Intel. Fonte: http://ais.informatik.uni-freiburg.de/publications/papers/valada17icra.pdf
I sistemi di sintesi di immagini di set di dati accoppiati funzionano correlando etichette semantiche su due set di dati: un set di immagini completo e completo, generato da immagini del mondo reale (come con il set Mapillary utilizzato per migliorare GTA5 nella demo Intel di ieri) o da immagini sintetiche, come le immagini CGI.

Esempi di set di dati accoppiati per un sistema di sintesi di immagini progettato per creare personaggi con rendering neurale da schizzi goffi. A sinistra, esempi dal set di dati CGI. Campioni centrali corrispondenti dal set di dati “schizzo”. Esatto, rendering neurali che hanno tradotto gli schizzi in immagini di alta qualità . Fonte: https://www.youtube.com/watch?v=miLIwQ7yPkA
Gli ambienti esterni sono relativamente poco impegnativi quando si creano trasformazioni di set di dati accoppiati di questo tipo, perché le sporgenze sono generalmente piuttosto limitate, la topografia ha una gamma limitata di varianza che può essere acquisita in modo completo in un set di dati e non dobbiamo occuparci della creazione di persone artificiali , o negoziando la Uncanny Valley (ancora).
Inversione delle mappe di segmentazione
Google ha sviluppato una versione animata dello schema GauGAN, chiamata Infinite Nature , in grado di “ allucinare ” deliberatamente paesaggi fittizi continui e senza fine traducendo false mappe semantiche in immagini fotorealistiche tramite il sistema di riempimento SPADE di NVIDIA :
Tuttavia, Infinite Nature utilizza una singola immagine come punto di partenza e utilizza SPADE semplicemente per dipingere nelle sezioni mancanti in fotogrammi successivi, mentre SPADE stesso crea trasformazioni di immagini direttamente dalle mappe di segmentazione.
Fonte: https://nvlabs.github.io/SPADE/
È questa capacità che sembra aver suscitato gli ammiratori del sistema Intel Image Enhancement: la possibilità di derivare immagini fotorealistiche di altissima qualità, anche in tempo reale (eventualmente), da input estremamente rozzi.
Sostituzione di texture e illuminazione con rendering neurale
Nel caso dell’input GTA5, alcuni si sono chiesti se una qualsiasi delle texture procedurali e bitmap e l’illuminazione computazionalmente costose dall’output del motore di gioco saranno davvero necessarie nei futuri sistemi di rendering neurale, o se potrebbe essere possibile trasformare le basse frequenze risoluzione, input a livello di wireframe in video fotorealistici che superano le capacità di ombreggiatura, texture e illuminazione dei motori di gioco, creando scene iperrealistiche dall’input proxy “segnaposto”.
Potrebbe sembrare ovvio che le sfaccettature generate dal gioco come i riflessi, le trame e altri tipi di dettagli ambientali siano fonti di informazioni essenziali per un sistema di rendering neurale del tipo dimostrato da Intel. Eppure sono passati alcuni anni da quando UNIT (Unsupervised Image-to-image Translation Networks) di NVIDIA ha dimostrato che solo il dominio è importante e che anche aspetti radicali come “notte o giorno” sono essenzialmente problemi da gestire con il trasferimento dello stile:
Day2NightImageTranslation-06
In termini di input richiesto, questo lascia potenzialmente il motore di gioco che deve solo generare la geometria di base e le simulazioni fisiche, poiché il motore di rendering neurale può sovrascrivere tutti gli altri aspetti sintetizzando le immagini desiderate dal set di dati catturato, utilizzando mappe semantiche come interpretazione strato.
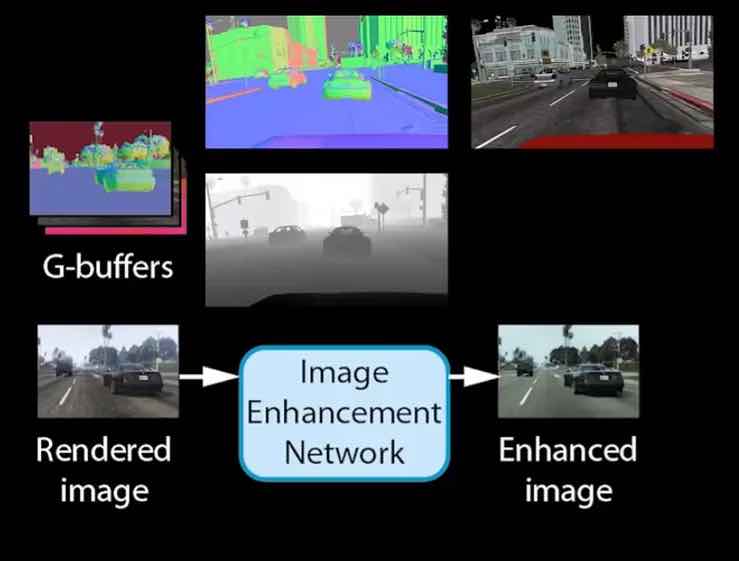
Il sistema Intel migliora un frame completamente finito e renderizzato da GTA5, aggiungendo segmentazione e mappe di profondità valutate, due aspetti che potrebbero essere forniti direttamente da un motore di gioco ridotto al minimo. Fonte: https://www.youtube.com/watch?v=P1IcaBn3ej0
L’approccio di rendering neurale di Intel prevede l’analisi di fotogrammi completamente renderizzati dai buffer GTA5 e il sistema neurale ha l’onere aggiuntivo di creare sia le mappe di profondità che le mappe di segmentazione. Poiché le mappe di profondità sono implicitamente disponibili nelle tradizionali pipeline 3D (e sono meno impegnative da generare rispetto al texturing, al ray-tracing o all’illuminazione globale), potrebbe essere un uso migliore delle risorse lasciare che il motore di gioco le gestisca.
Input ridotto per un motore di rendering neurale
L’attuale implementazione della rete di miglioramento dell’immagine Intel, quindi, può comportare una grande quantità di cicli di elaborazione ridondanti, poiché il motore di gioco genera texture e illuminazione costose dal punto di vista computazionale di cui il motore di rendering neurale non ha realmente bisogno. Il sistema sembra essere stato progettato in questo modo non perché questo sia necessariamente un approccio ottimale, ma perché è più facile adattare un motore di rendering neurale a una pipeline esistente piuttosto che creare un nuovo motore di gioco ottimizzato per un approccio di rendering neurale.
L’uso più economico delle risorse in un sistema di gioco di questa natura potrebbe essere la cooptazione completa della GPU da parte del sistema di rendering neurale, con l’input proxy ridotto gestito dalla CPU.
Inoltre, il motore di gioco potrebbe facilmente produrre mappe di segmentazione rappresentative, disattivando tutte le ombreggiature e l’illuminazione nel suo output. Inoltre, potrebbe fornire video a una risoluzione molto inferiore a quella normalmente richiesta, poiché il video dovrebbe essere solo ampiamente rappresentativo del contenuto, con dettagli ad alta risoluzione gestiti dal motore neurale, liberando ulteriormente le risorse di elaborazione locali.
Il lavoro precedente di Intel ISL con la segmentazione> Immagine
La traduzione diretta della segmentazione in video fotorealistico è tutt’altro che ipotetica. Nel 2017 Intel ISL, creatori del furore di ieri, ha pubblicato una ricerca iniziale in grado di eseguire la sintesi video urbana direttamente dalla segmentazione semantica.

La segmentazione di Intel ISL per l’immagine funziona dal 2017. Fonte: https://awesomeopensource.com/project/CQFIO/PhotographicImageSynthesis
In effetti, quella pipeline originale del 2017 è stata semplicemente estesa per adattarsi all’output completamente renderizzato di GTA5.
Sintesi di immagini fotografiche con reti di raffinamento a cascata
Rendering neurale in VFX
Anche il rendering neurale da mappe di segmentazione artificiale sembra essere una tecnologia promettente per VFX, con la possibilità di tradurre direttamente videogrammi di base direttamente in filmati di effetti visivi finiti, generando set di dati specifici del dominio presi da modelli o immagini sintetiche (CGI).

Un ipotetico sistema di rendering neurale, in cui un’ampia copertura di ogni oggetto target viene astratta in un insieme di dati che contribuisce e in cui le mappe di segmentazione generate artificialmente vengono utilizzate come base per l’output fotorealistico a piena risoluzione. Fonte: https://rossdawson.com/futurist/implications-of-ai/comprehensive-guide-ai-artificial-intelligence-visual-effects-vfx/
Lo sviluppo e l’adozione di tali sistemi sposterebbero il luogo dello sforzo artistico da un flusso di lavoro interpretativo a uno rappresentativo ed eleverebbero la raccolta di dati guidata dal dominio da un ruolo di supporto a un ruolo centrale nelle arti visive.